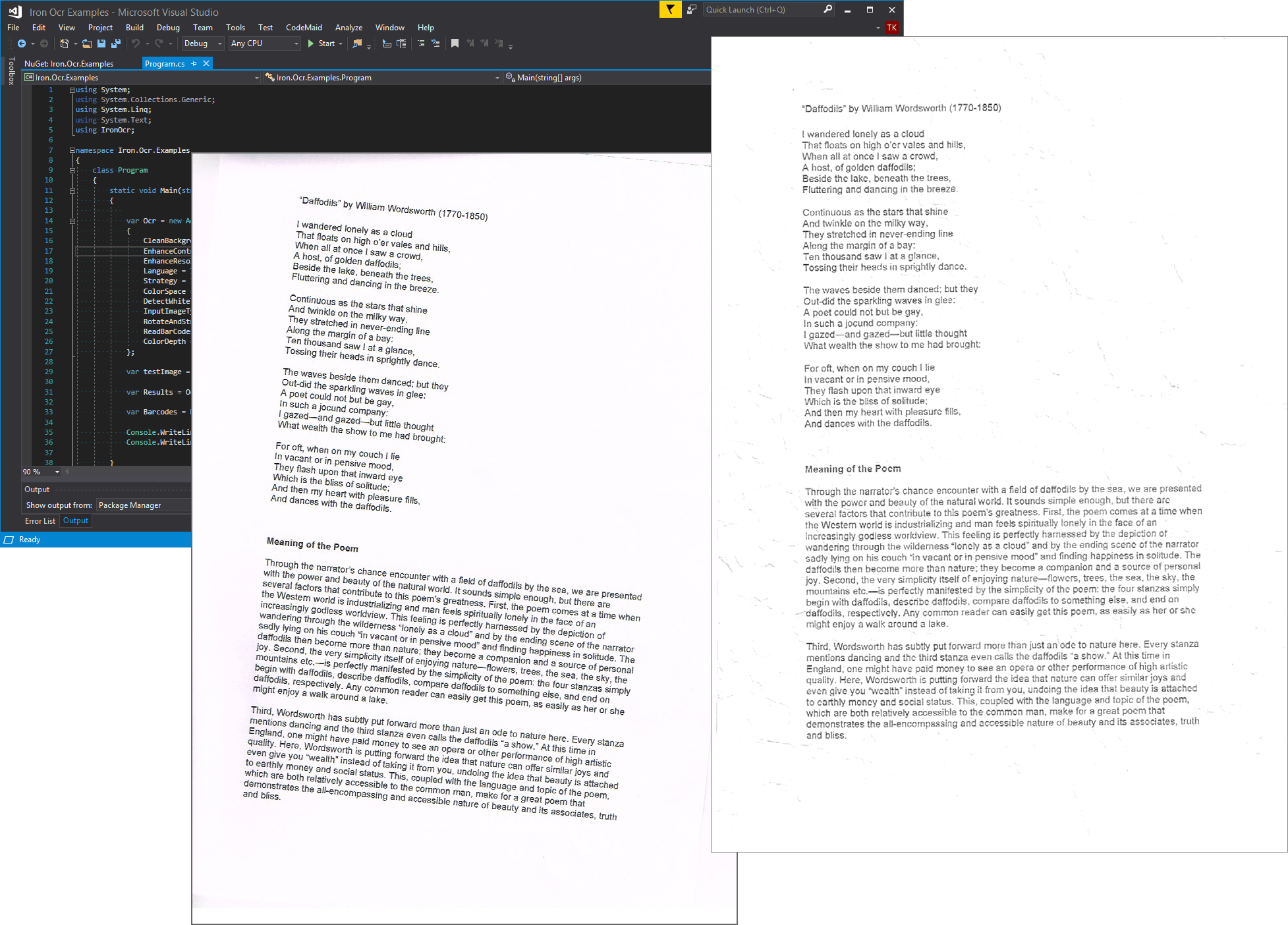
Tổng quan
IronOCR for.NET tập trung vào bài toán đọc văn bản từ hình ảnh và PDF trong ứng dụng.NET và website. Thư viện hỗ trợ nhận dạng text, barcode và QR từ ảnh quét, đồng thời trả kết quả dưới dạng plain text, structured data hoặc searchable PDF.
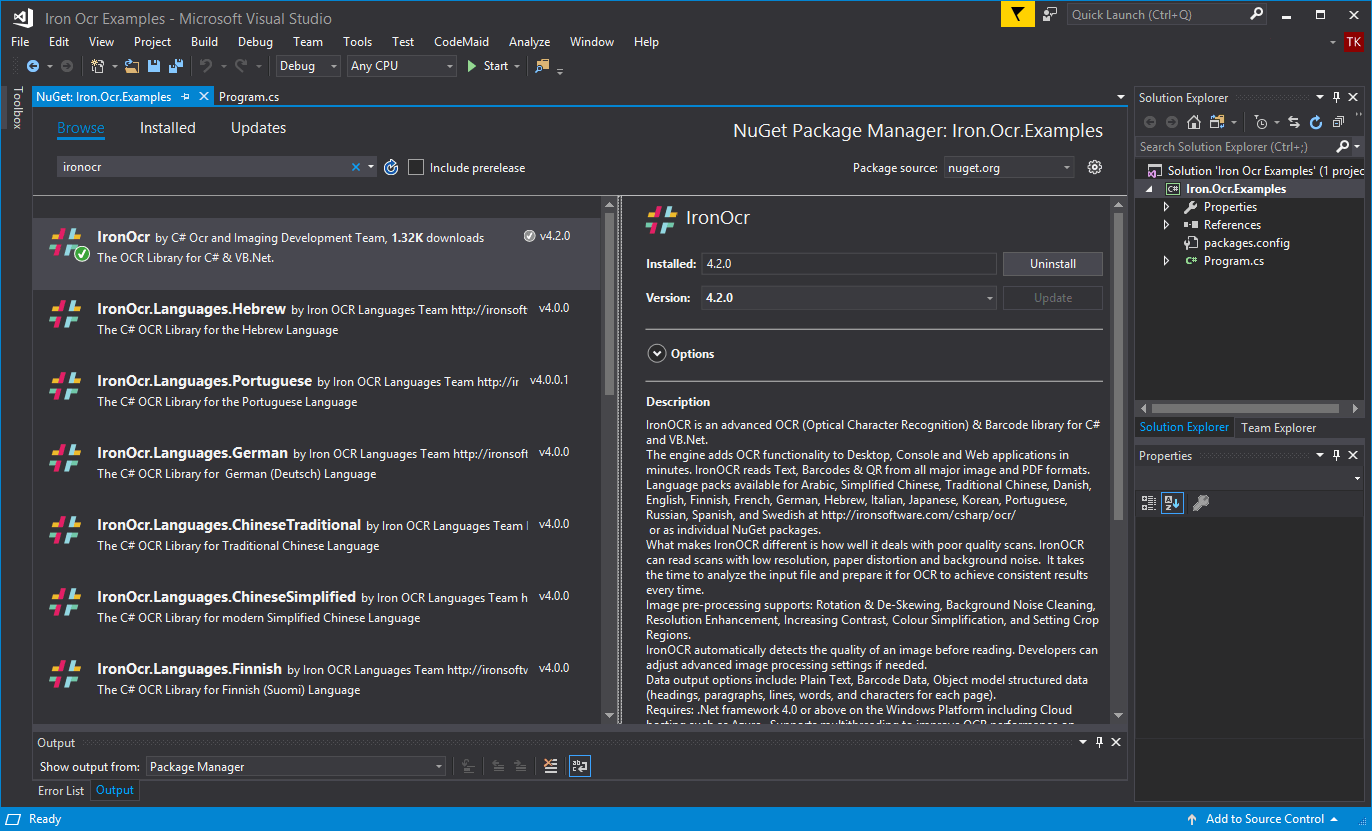
Nền tảng OCR sử dụng Tesseract 5 tùy biến cho.NET và vận hành hoàn toàn cục bộ. Cách tiếp cận này phù hợp với các hệ thống cần xử lý OCR local thay vì phụ thuộc dịch vụ SAAS.
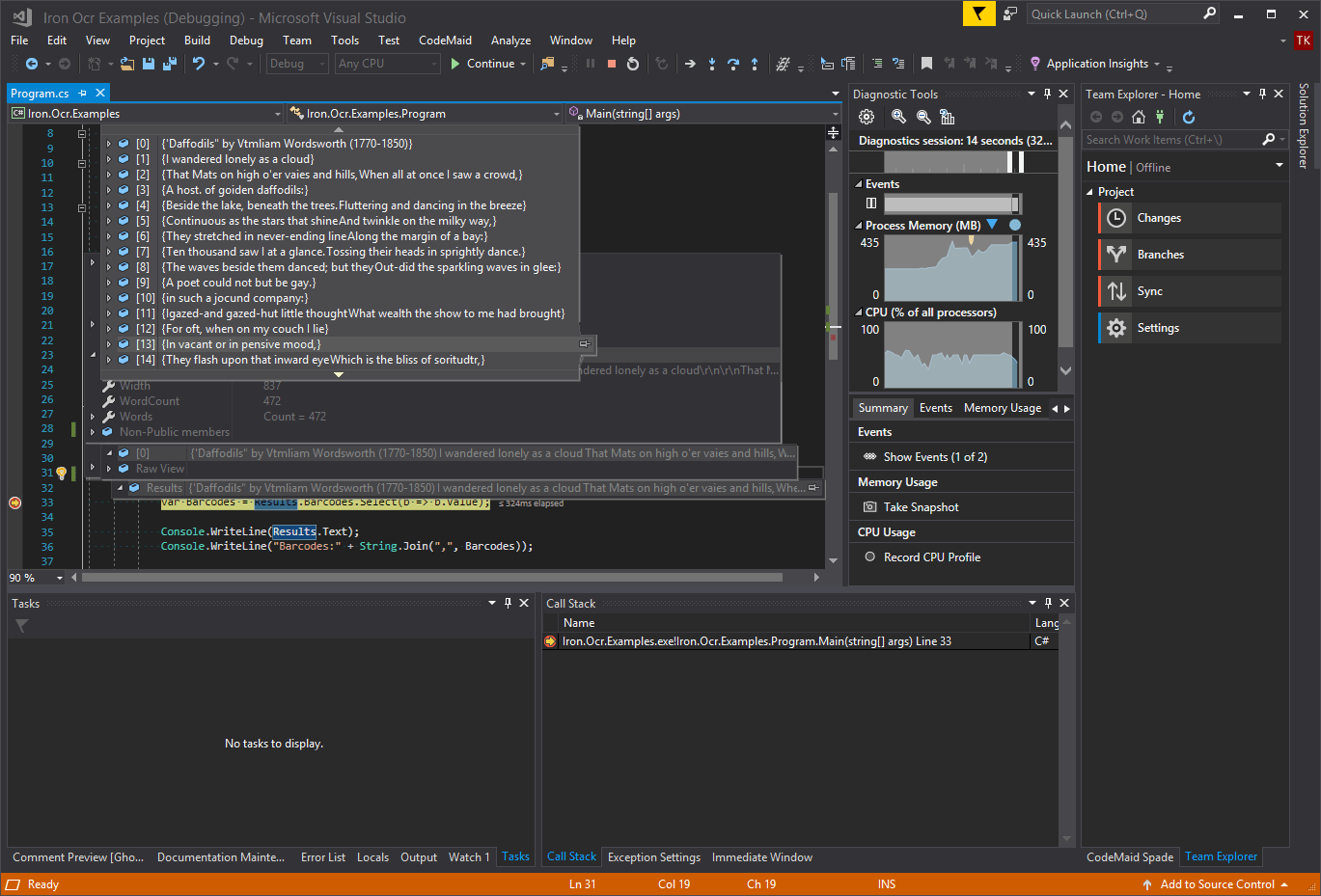
Thư viện OCR cho.NET dùng Tesseract 5 để đọc văn bản, barcode và QR từ ảnh, PDF. Hỗ trợ 127+ ngôn ngữ, xuất plain text, structured data và searchable PDF.
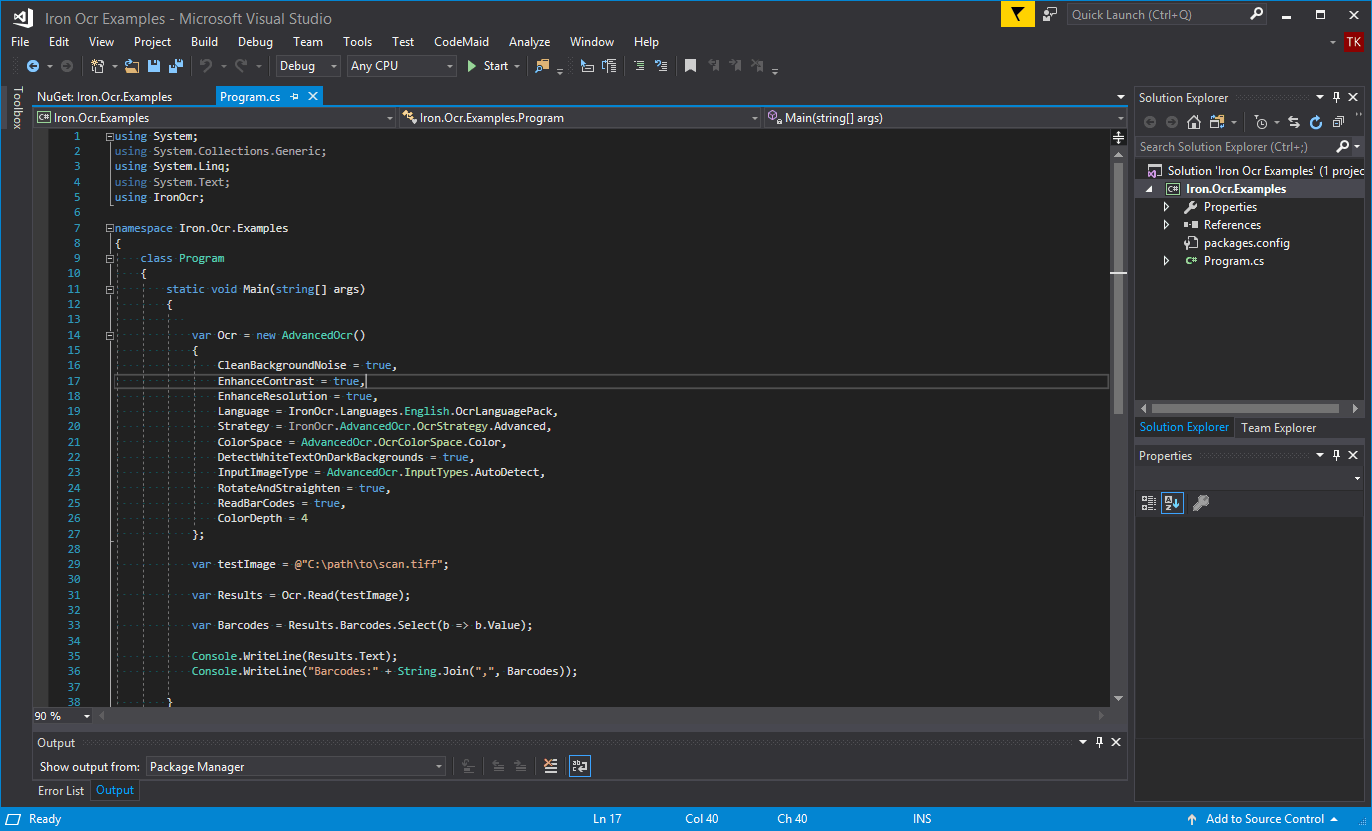
Tính năng nổi bật
- Đọc text, barcode và QR từ ảnh và PDF bằng Tesseract 5.
- Chạy OCR cục bộ với Pure.NET OCR API, không dùng SAAS.
- Hỗ trợ 127+ ngôn ngữ cho tài liệu quốc tế và nội dung đa ngữ.
- Nhận dạng nhiều ngôn ngữ cùng lúc trong một lần xử lý.
- Tạo custom language packs để mở rộng bộ ngôn ngữ OCR.
- Sửa ảnh quét nhiễu, méo và chất lượng thấp trước khi nhận dạng.
- Đọc PDF và multi-page TIFF cho tài liệu nhiều trang.
Ứng dụng thực tế
- Số hóa tài liệu quét trong hệ thống quản lý hồ sơ.NET.
- Trích xuất văn bản từ PDF và ảnh để lập chỉ mục tìm kiếm.
- Đọc barcode và QR trong quy trình nhập liệu tự động.
- Xử lý bảng trong tài liệu phục vụ trích xuất dữ liệu có cấu trúc.
- Nhận dạng biển số xe, hộ chiếu, ảnh chụp màn hình và ảnh tài liệu.
Đối tượng sử dụng phù hợp
- Lập trình viên.NET xây dựng ứng dụng OCR nội bộ hoặc thương mại
- Dev lead cần tích hợp OCR local vào MVC, Web, console hoặc desktop apps
- Nhóm kỹ thuật xử lý document digitization và text processing
- Technical buyer tìm thư viện OCR cho môi trường Windows, macOS hoặc Linux
Thông tin kỹ thuật
Câu hỏi thường gặp
IronOCR for.NET dùng engine OCR nào?
Thư viện sử dụng Tesseract 5 tùy biến cho.NET.
Có cần dùng dịch vụ cloud hoặc SAAS để chạy OCR không?
Không. Các tác vụ OCR chạy locally và không dùng SAAS.
IronOCR có xử lý được PDF và TIFF nhiều trang không?
Có. Thư viện hỗ trợ đọc PDFs và multi-page TIFFs, cùng multi-frame TIFF và GIF.
Kết quả OCR có thể xuất ra những dạng nào?
Có thể xuất plain text, barcode data, OCR Result class, searchable PDF, hOCR và HTML.
Những IDE và nền tảng.NET nào được hỗ trợ?
Có hỗ trợ Microsoft Visual Studio 2012-2026, JetBrains ReSharper, Rider và các nền tảng từ.NET Framework 4.6.2+ đến.NET 10.




Bình luận